2.2 Version Control
Version control is a system that records changes to a file or set of files over time, to be able to recall specific versions later. It is an essential tool for any software development project as it allows multiple developers to work together, track changes, and easily rollback in case of errors. There are two main types of version control systems: centralized and distributed.
Centralized Version Control Systems (CVCS) : In a centralized version control system, there is a single central repository that contains all the versions of the files, and developers must check out files from the repository in order to make changes. Examples of CVCS include Subversion and Perforce.
Distributed Version Control Systems (DVCS) : In a distributed version control system, each developer has a local copy of the entire repository, including all the versions of the files. This allows developers to work offline, and it makes it easy to share changes with other developers. Examples of DVCS include Git, Mercurial and Bazaar
Version control is a vital component of software development that offers several benefits. First, it keeps track of changes made to files, enabling developers to revert to a previous version in case something goes wrong. Collaboration is also made easier with version control, as it allows multiple developers to work on a project simultaneously and share changes with others. In addition, it provide backup capabilities by keeping a history of all changes, allowing you to retrieve lost files. Version control also allows auditing of changes, tracking who made a specific change, when, and why. Finally, it enables developers to create branches of a project, facilitating simultaneous work on different features without affecting the main project, with merging later.
Versioning all components of a machine learning project, such as code, data, and models, is essential for reproducibility and managing models in production. While versioning code-based components is similar to typical software engineering projects, versioning machine learning models and data requires specific version control systems. There is no universal standard for versioning machine learning models, and the definition of “a model” can vary depending on the exact setup and tools used.
Popular tools such as Azure ML, AWS Sagemaker, Kubeflow, and MLflow offer their own mechanisms for model versioning. For data versioning, there are tools like Data Version Control (DVC) and Git Large File Storage (LFS). The de-facto standard for code versioning is Git. The code-versioning system Github is used for this project, which will be depicted in more detail in the following.
2.2.1 Github
GitHub provides a variety of branching options to enable flexible collaboration workflows. Each branch serves a specific purpose in the development process, and using them effectively can help teams collaborate more efficiently and effectively.

Main Branch: The main branch is the default branch in a repository. It represents the latest stable version and production-ready state of a codebase, and changes to the code are merged into the main branch as they are completed and tested. Feature Branch: A feature branch is used to develop a new feature or functionality. It is typically created off the main branch, and once the feature is completed, it can be merged back into the main branch. Hotfix Branch: A hotfix branch is used to quickly fix critical issues in the production code. It is typically created off the main branch, and once the hotfix is completed, it can be merged back into the main branch. Release Branch: A release branch is a separate branch that is created specifically for preparing a new version of the software for release. Once all the features and fixes for the new release have been added and tested, the release branch is merged back into the main branch, and a new version of the software is tagged and released.
2.2.2 Git lifecycle
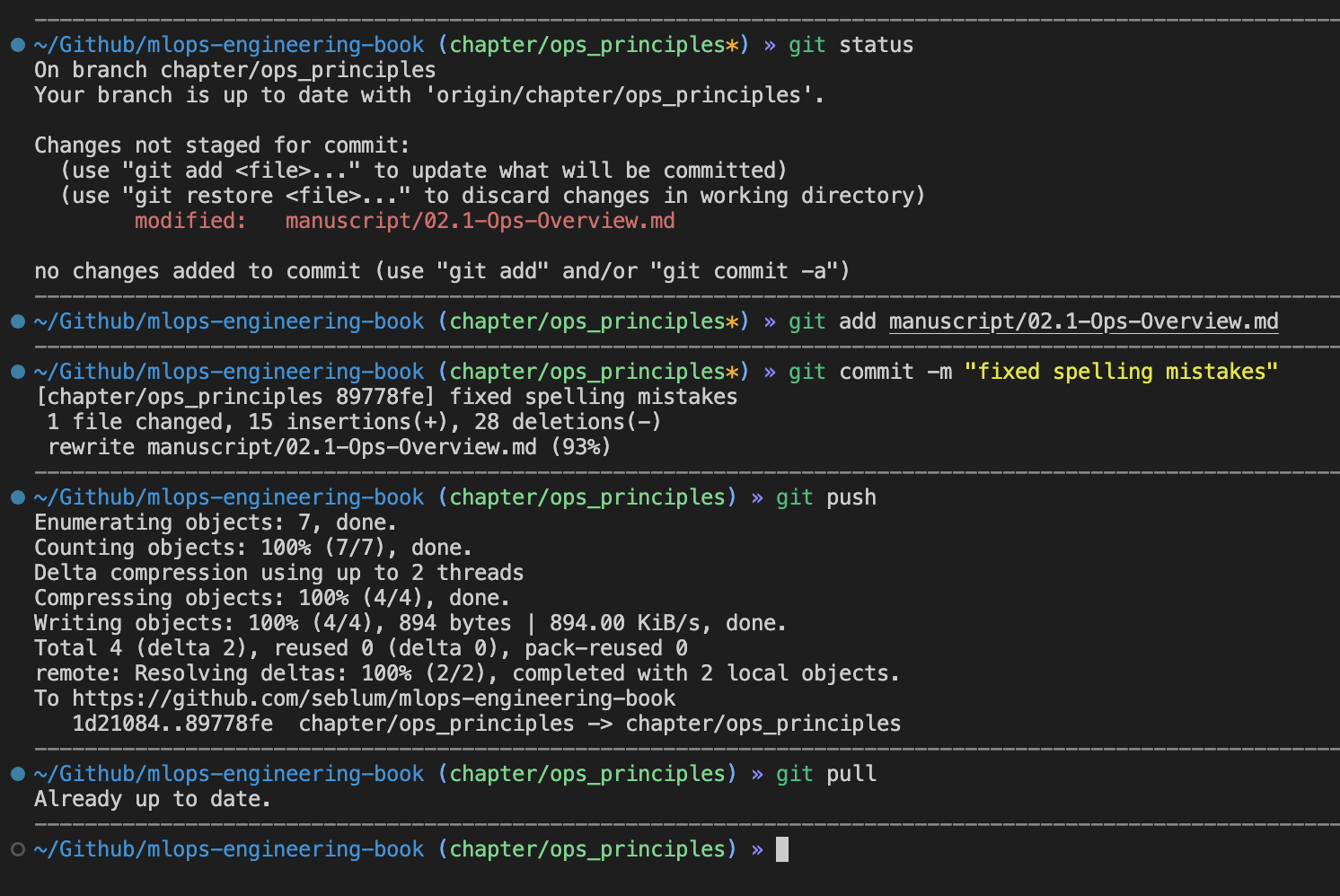
After a programmer has made changes to their code, they would typically use Git to manage those changes through a series of steps. First, they would use the command git status to see which files have been changed and are ready to be committed. They would then stage the changes they want to include in the commit using the command git add <FILE-OR-DIRECTORY>, followed by creating a new commit with a message describing the changes using git commit -m "MESSAGE".
After committing changes locally, the programmer may want to share those changes with others. They would do this by pushing their local commits to a remote repository using the command git push. Once the changes are pushed, others can pull those changes down to their local machines and continue working on the project by using the command git pull.
If the programmer is collaborating with others, they may need to merge their changes with changes made by others. This can be done using the git merge <BRANCH-NAME> command, which combines two branches of development history. The programmer may need to resolve any conflicts that arise during the merge.
If the programmer encounters any issues or bugs after pushing their changes, they can use Git to revert to a previous version of the code by checking out an older commit using the command git checkout. Git’s ability to track changes and revert to previous versions makes it an essential tool for managing code in collaborative projects.
While automating the code review process is generally viewed as advantageous, it is still typical to have a manual code review as the final step before approving a pull or merge request to be merged into the main branch. It is considered a best practice to mandate a manual approval from one or more reviewers who are not the authors of the code changes.